Monitoring and collecting syslog messages from Unix Domain Socket
Application log is the traditional way to monitor an application/service. On *nix-based system, Syslog is a common but powerful tool for centrally monitoring applications logs. The primary use of syslog is for system management as capturing log data is critical for sysadmin, devOp team, or system analysts, etc. This log data is helpful in case of investigating/troubleshooting problems and maintaining healthy functioning of systems.
Syslog offers a standard log format and a standard alert system with different severity levels to applications in form of a log API. Log daemons such as rsyslog are versatile and flexible with various configuration options that enable different way to interact with the logs: log to file, log to a remote server via network (TCP, UDP sockets), log to local Unix domain socket. Log clients or log analytic applications can collect log data from the log daemon via these interfaces.
Although it is feasible to directly read log messages from the regular syslog output files, it is more preferable to collect log data from the daemon using the socket interface since socket is more suitable for data streaming. TCP/UDP sockets can be used to access log data from the network (TCP/IP). But if the application runs locally on the same machine as the log daemon, Unix domain socket (UDS) may be the best option.
Unix Domain Socket is an inter-process communication mechanism that allows bidirectional data exchange between processes running on the same machine. Thus, UDSs can avoid some checks and operations (like routing); which makes them faster and lighter than IP sockets.
In this post, we will learn how to collect log data from syslog via UDS in C. We will use rsyslog as log daemon in this post.
A use case will be presented at the end of the post.
sysmond: Simple service for (embedded) Linux system monitoring
Working on my DIY robot software (Jarvis) in headless mode, i came across a situation where i needed to monitor the system resource such as CPU, battery, memory, network and temperature to measure the "greedy" of my robotic application. Furthermore, as the robot was battery powered, battery safety was a real concern, so i needed something to monitor the battery and shutdown the system when the battery was low to protect it from falling bellow the usable voltage range.
So i've searched for an application/service that allows me to:
- Monitor system memory, CPU, storage usage and temperature
- Monitor network consumption
- Monitor the robot battery and power off the system if the battery is low
None of existing applications/services satisfy all of these requirements, especially, the battery monitoring feature. So i've decided to write a small service that i called sysmond.
sysmond is a simple service that monitors and collects system information such as battery, temperature, memory, CPU, and network usage. The service can be used as backend for applications that need to consult system status. Although it is a part of Jarvis ecosystem, sysmond is a generic service and can be easily adapted to other use cases.
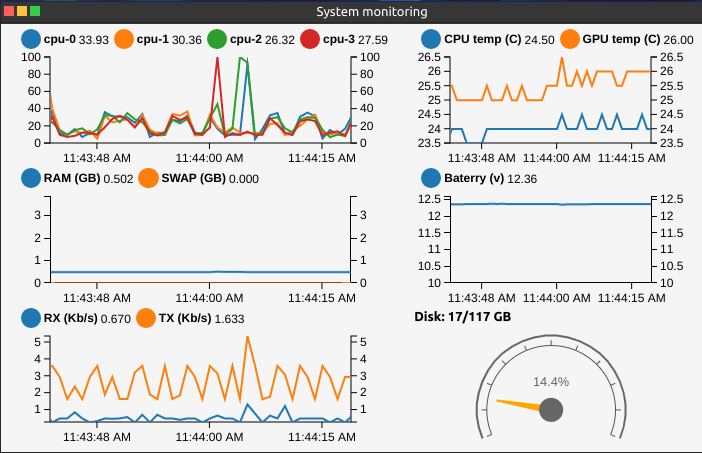
Example of AntOS web application that fetches data from sysmond and visualize it as real-time graphs on my Jarvis robot system. Detail on the use case can be found here
Sysmond monitors resource available on the system via the user space sysfs interface provided by the linux kernel.
Running your own AntOS VDE system using a Docker image
Update: The image is now available on Docker Hub at: https://hub.docker.com/r/xsangle/antosaio (image:
xsangle/antosaio:latest). This post has been updated with the latest instructions on how to host a local instance of AntOS VDE using Docker.
Building and setting up AntOS from scratch can be complex, as it requires configuring and connecting many backend and front-end components. To simplify the use of AntOS as a self-hosted environment, I have created a Docker image layer for an all-in-one AntOS system that contains everything needed to host AntOS on your server. This layer allows you to build a minimal Docker image with a working AntOS system out-of-the-box:
- The web server (HTTP/HTTPS depending on the server configuration) + plugins
- AntOS server-side API
- AntOS client-side API
The Docker images are available at: https://hub.docker.com/r/xsangle/antosaio/
How does it work?
Follow the steps below to create an AntOS instance. First, create the working directory (e.g., /tmp/antos). All user data will be stored in this location. In this example, we use /tmp/antos, but in a real scenario, you should use a permanent storage location.
# modify with your own working directory
mkdir -p /tmp/antos
Run a container with docker
docker run \
-p 8080:80 \
--rm \
-v /tmp/antos:/app \
-e ANTOS_USER=demo \
-e ANTOS_PASSWORD=demo \
-it xsangle/antosaio:latest
Or with docker compose: docker-compose.yml
version: '3.7'
services:
antos:
image: xsangle/antosaio:latest
privileged: true
restart: always
ports:
- 8080:80
container_name: antos_demo
deploy:
resources:
limits:
memory: 200m
cpus: '0.5'
hostname: demo
environment:
- ANTOS_USER=demo
- ANTOS_PASSWORD=demo
volumes:
- /tmp/antos/:/app
Run:
docker compose up
AntOS is now accessible via http://localhost:8080/os/ or using IP address http://YOUR_MACHINE_IP:8080/os/
Conclusion
The docker image provides user with a ready to go (out-of-the-box) AntOS VDE system. This is useful in many user-cases:
- Quickly setup environment for AntOS applications development
- Scalable multi-user cloud-base service with AntOS and Kubenetes. Alternative to Ownclod, Google Cloud, Dropbox etc, with a more intuitive and user-friendly GUI, and more applications
Evaluation of grid maps produced by a SLAM algorithm
When evaluating the performance of a SLAM algorithm, quantifying the produced map quality is one of the most important criteria. Often, the produced map is compared with (1) a ground-truth map (which can be easily obtained in simulation) or (2) with another existing map that is considered accurate (in case of real world experiment where the ground-truth is not always available ).
Basically, grid maps are images, so image similarity measurement metrics can be used in this case. In this post, we consider three different metrics: Mean Square Error (MSE), K-nearest based normalized error (NE) and Structure Similarity Index (SSIM)
Simple (naive) document clustering using tf-idf and k-mean
When i developed this blog (using my own client-server platform such as web server, back-end, front-end, etc., built from ash/scratch :) ), i simply designed it as a simple "note book" where i put my ideas or some stuffs that i have done. So, initially, there are no category no advance feature like post suggestion based on current post, etc. It is just a bunch of posts sorting by date. The thing is, i usually work on many different domains (robotic, IoT, backend, frontend platform design, etc.), so my posts are mixed up between different categories. It is fine for me, but is a real inconvenience for readers who want to follow up their interesting category on the blog. Of course, i could redesign the blog and add the missing features by messing around with the relational database design (i'm using SQLite btw), manually classifying the posts in the back-end, etc. But, i'm a kind of lazy people, so i've been thinking of a more automatic solution. How about an automatic document clustering feature based on a data mining approach ? Here we go!
Programming LPC1114FN28 with standard C using Newlib
Some of my old posts show how to program the ARM Cortex M0 LPC chip in a bare metal manner, although this approach provides a simple setup that requires no additional libraries, it is only for the studying purpose. It is not a good options for production since your code will be highly platform dependent and you need to handle so many low level stuffs (e.g. registers configuration). The Newlib offers a more productive way by providing a standard C interface to abstract the development on such embedded system. In using Newlib, the code is a lot simpler and more portable.